2022. 1. 4. 00:13ㆍStudy/Database

Part 1. 표준조인 STANDARD JOIN
1. STANCARD JOIN 개요
- 기업형 DBMS는 대부분 객체지원 기능이 포함된 객체관계형 데이터베이스 사용
- 현재 DB는 대부분 SQL-2003 기준
ANSI/ISO 표준 SQL 기능?
- STANDARD JOIN 기능 추가 (CROSS, OUTER JOIN 등)
- SCALAR SUBQUERY, TOP-N QUERY 등 서브쿼리 기능
- ROLL UP, CUBE, GROUPING SETS 등 리포팅 기능
- WINDOW FUNCTION 등 분석 기능
가. 일반 집합 연산자
- UNION : 합집합
- INTERSECTION : 교집합
- DIFFRENCE : 차집합 (ORACLE : MINUS, 그 외 : EXCEPT)
- PRODUCT : 곱집합
나. 순수 관계 연산자
- SELECT 연산 : WHERE 절로 구현
- PROJECT 연산 : SELECT 절로 구현
- (NATURAL) JOIN 연산 : JOIN 기능으로 구현
- DIVIDE 연산 : 현재 사용 안함
2. FROM 절 JOIN - INNER JOIN
- JOIN 조건에서 동일한 값이 있는 행만 반환
- UNSING 또는 ON 조건절을 필수적으로 사용
- * 사용 시, 테이블 순서대로 컬럼 출력
- 동일 명의 컬럼은 별개의 컬럼으로 처리
SELECT *
FROM TB1 (INNER) JOIN TB2
ON TB1.NAME = TB2.NAME;
3. FROM 절 JOIN - NATURAL (EQUI) JOIN
- 두 테이블 간 동일한 이름을 갖는 모든 컬럼들에 대해 EQUI JOIN 수행
- USING, ON, WHERE 에서 JOIN 조건 정의 불가
- SQL Server 에서는 지원하지 않음
- 접두사 사용 불가 (TB.COLUMN_NAME)
- * 사용 시, NATURAL JOIN 의 기준이 되는 컬럼들이 다른 컬럼보다 먼저 출력
- 동일 명의 컬럼을 하나로 처리
SELECT *
FROM TB1 NATURAL JOIN TB2;4. FROM 절 JOIN - USING 조건절
- 같은 이름을 가진 컬럼들 중에서 원하는 컬럼에 대해서만 선택적으로 EQUI JOIN
- SQL Server 에서는 지원하지 않음
- * 사용 시, USING 조건절의 기준이 되는 컬럼이 다른 컬럼보다 먼저 출력
SELECT *
FROM TB1 INNER JOIN TB2
USING (VALUE);5. FROM 절 JOIN - ON 조건절
- 컬럼명이 다르더라도 JOIN 조건을 사용할 수 있음
- 임의의 JOIN 조건 지정 가능
가. WHERE 절과의 혼용
- 충돌 없이 사용 가능
- 검색조건 목적인 경우에는 WHERE 절이 적합
나. ON 조건절 + 데이터 검증 조건 추가
- JOIN 조건 외에도 조건 추가 가능
- OUTER JOIN 에서 대상을 제한하기 위한 목적의 조건은 ON 절 사용
6. FROM 절 JOIN - CROSS JOIN
- JOIN 조건이 없는 경우 생길 수 있는 모든 데이터 조합 출력
- M * N 건의 데이터 조합 발생
- WHERE 절에 조건 추가 가능 ( EQUI 인 경우 INNER JOIN 과 결과 동일 )
- 튜닝이나 리포트 작성을 위해 고의적으로 사용하는 경우 있음
SELECT *
FROM TB1, TB2;
또는
SELECT *
FROM TB1 CROSS JOIN TB2;7. FROM 절 JOIN - OUTER JOIN
- JOIN 조건에서 동일한 값이 없는 행도 반환할 수 있음
가. LEFT (OUTER) JOIN
- 좌측 테이블 데이터를 먼저 읽은 후 우측 데이터에서 JOIN 대상 데이터를 읽어옴
- 우측 테이블에 값이 없는 경우, NULL 로 채움
SELECT *
FROM TB1 LEFT (OUTER) JOIN TB2
ON TB1.NAME = TB2.NAME;나. RIGHT (OUTER) JOIN
- 우측 테이블 데이터를 먼저 읽은 후 좌측 데이터에서 JOIN 대상 데이터를 읽어옴
- 좌측 테이블에 값이 없는 경우, NULL 로 채움
SELECT *
FROM TB1 RIGHT (OUTER) JOIN TB2
ON TB1.NAME = TB2.NAME;
다. FULL (OUTER) JOIN
- 좌측, 우측 테이블의 모든 데이터를 읽어 JOIN 하여 결과를 생성
- UNION 과 동일 (정렬, 중복제거)
SELECT *
FROM TB1 FULL (OUTER) JOIN TB2
ON TB1.NAME = TB2.NAME;
Part 2. 집합 연산자
- 서로 다른 테이블에서 유사한 형태의 결과를 반환하여 하나의 결과로 합칠 때
- 동일 테이블에서 서로 다른 질의를 수행하여 결과를 합칠 때
- 실행 계획을 분리할 때 사용
| 집합 연산자 | 의미 |
| UNION | 합집합, 중복된 행은 하나의 행으로 처리 |
| UNION ALL | 합집합, 중복된 행도 결과로 표시 |
| INTERSECT | 교집합, 중복된 행은 하나의 행으로 처리 = EXISTS, IN (SUB QUERY) |
| MINUS/EXCEPT | 차집합, 중복된 행은 하나의 행으로 처리 = NOT EXISTS, NOT IN (SUB QUERY) |
Part 3. 계층형 질의, 셀프조인
1. 계층형 질의
- 계층형 데이터가 존재하는 경우 사용
- 계층형 데이터 : 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터
가. Oracle 계층형 질의
SELECT ...
FROM TABLE_NAME
WHERE ...
START WITH PARENT_COLUMN
CONNECT BY [NOCYCLE] CHILD_COLUMN AND ...
[ORDER SIBLINGS BY COLUMN_NAME, ...];- START WITH : 시작 위치를 지정하는 구문, 루트 데이터 지정
- CONNECT BY : 다음에 전개될 자식 데이터를 지정하는 구문, 조인 조건
- PRIOR : CONNECT BY 절에 사용, 현재 읽은 컬럼을 지정
• PRIOR 자식 = 부모 → 자식 데이터에서 부모 데이터 방향으로 전개하는 순방향 전개
• PRIOR 부모 = 자식 → 부모 데이터에서 자식 데이터 방향으로 전개하는 역방향 전개
- NOCYCLE : 이미 나타났던 동일한 데이터가 나타나는 경우, 이후에는 전개하지 않음
- ORDER SIBLINGS BY : 형제노드 (동일 LEVEL) 사이에서 정렬 수행
- WHERE : 모든 전개 수행 후 조건을 만족하는 데이터만 추출
- ORACLE 에서 제공하는 가상 컬럼
| 가상컬럼 | 설명 |
| LEVEL | ROOT 면 1, 그 하위 데이터면 1씩 증가 |
| CONNECT_BY_ISLEAF | 해당 데이터가 리프 데이터이면 1, 아니면 0 |
| CONNECT_BY_ISCYCLE | 해당 데이터가 조상으로써 존재하면 1, 아니면 0, CYCLE 옵션을 사용했을 때만 사용 가능 |
- ORACLE 에서 제공하는 계층형 질의 함수
| 함수 | 설명 |
| SYS_CONNECT_BY_PATH(COLUMN_NAME, 경로분리자) | 루트 데이터부터 현재 데이터까지의 경로 |
| CONNECT_BY_ROOT COLEUMN_NAME | 현재 전개할 데이터의 루트 데이터 표시, 단항연산자 |
나. SQL Server 계층형 질의
- 앵커멤버 + 재귀멤버 구조
WITH WITH_NAME AS (
/* Anchor Member */
SELECT COLUMN_NAME, ...
FROM TABLE_NAME
WHERE PARENT_COLUMN IS NULL /* 재귀호출 시작점 */
UNION ALL
/* Recursive Member */
SELECT COLUMN_NAME, ...
FROM WITH_NAME A, TABLE_NAME B
WHERE A.CHILD_COLUMN = B.PARENT_COLUMN
)
SELECT ....
FROM WITH_NAME
WHERE ...;- 별도 정렬 필요함
2. 셀프 조인
- 동일 테이블 사이의 조인
- FROM 절에 동일 테이블이 두번 이상
- 반드시 테이블 ALIAS 를 사용해야 함
Part 4. 서브쿼리
1. 서브쿼리 개요
- 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문
- 알려지지 않은 기준을 이용한 검색을 위해 사용
- 메인쿼리가 서브쿼리를 포함하는 종속적인 관계
- 서브쿼리는 메인쿼리의 컬럼을 모두 사용할 수 있음
서브쿼리 사용 시 주의사항
- 괄호로 감싸서 사용
- 단일행 또는 복수행 비교 연산자와 함게 사용 가능
- 서브쿼리에서는 ORDER BY 사용 불가
- SELECT, FROM, WHERE, HAVING, ORDER BY, INSERT 문의 VALUES, UPDATE 문의 SET 절에 사용 가능
가. 동작 방식에 따른 분류
| 서브쿼리 | 설명 |
| Un-Correlated(비연관) 서브쿼리 | 서브쿼리가 메인쿼리 컬럼을 가지고 있지 않는 형태, 메인쿼리에 값을 제공하기 위한 목적 |
| Correlated(연관) 서브쿼리 | 서브쿼리가 메인쿼리 컬럼을 가지고 있는 형태, 조건이 맞는지 확인하기 위한 목적 |
나. 반환 데이터 형태에 따른 문류
| 서브쿼리 | 설명 |
| Single Row(단일행) 서브쿼리 | 결과가 항상 1건 이하인 서브쿼리, 단일행 비교 연산자와 함께 사용 |
| Multi Row(다중행) 서브쿼리 | 결과가 여러 건인 서브쿼리, 다중행 비교 연산자와 함께 사용 |
| Multi Colum(다중열) 서브쿼리 | 여러 컬럼을 반환, 비교하고자 하는 컬럼 개수와 위치가 동일해야함 |
- 다중행 비교 연산자
| 다중행 비교 연산자 | 설명 |
| IN(서브쿼리) | 서브쿼리 결과에 존재하는 값과 일치하는 조건 |
| 비교연산자 ALL(서브쿼리) | 서브쿼리 결과에 존재하는 모든 값을 만족하는 조건 ex) > ALL(서브쿼리) 인 경우, 모든 값을 만족해야 하므로 최대값보다 큰 모든 건 |
| 비교연산자 ANY(서브쿼리) | 어느 하나의 값이라도 일치하는 조건 ex) > ANY(서브쿼리) 인 경우, 하나 이상 만족해야 하므로 최소값보다 큰 모든 건 |
| EXISTS(서브쿼리) | 서브쿼리 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건, 1건만 찾으면 더이상 검색하지 않음 |
2. 그 외
가. SCALAR SUBQUERY
- SELECT 절에서 사용되는 서브쿼리
- 한 행, 한 컬럼만 반환
나. INLINE VIEW
- FROM 절에서 사용되는 서브쿼리
- 동적 뷰
다. HAVING 절
- 그룹핑 된 결과에 대해 부가적인 조건을 주기 위해 사용
라. UPDATE 문의 SET 절
- 서브쿼리 결과로 UPDATE
- 서브쿼리의 결과가 NULL을 반환할 경우, NULL이 세팅됨
마. INSERT 문의 VALUES 절
- 서브쿼리 결과로 INSERT
3. 뷰 VIEW
- 정의 만을 가지고 있음
- 실제 데이터를 가지고 있지 않음
- 정의를 참조해서 DBMS 내부적으로 SQL을 재작성 하여 수행
- 가상테이블
| 장점 | 설명 |
| 독립성 | 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 됨 |
| 편리성 | SQL을 단순하게 작성 가능 |
| 보안성 | 숨기고 싶은 정보가 존재하는 경우, 뷰 생성 시 해당 컬럼을 제외해고 생성하여 정보를 숨김 |
가. 뷰 생성
CREATE VIEW VIEW_NAME
AS SELECT_QUERY;- 이미 존재하는 뷰를 참조해서도 생성 가능
나. 뷰 제거
DROP VIEW VIEW_NAME;
Part 5. 그룹 함수
1. 데이터 분석 개요
- 데이터 분석을 위한 함수 정의
가. AGGREGATE FUNCTION
- 집계함수
- COUNT, SUM, AVG, MAX, MIN 등
나. GROUP FUNCTION
- 소계/합계 표시를 위해 GROUPING 함수, CASE 함수 사용
- GROUPING 함수
• ROLLUP 함수 : 소그룹 간 소계 계산
• CUBE 함수 : GROUP BY 항목들 간 다차원적인 소계 계산
• GROUPING SETS 함수 : 특정항목에 대한 소계 계산
다. WINDOW FUNCTION
- 분석함수, 순위함수
2. ROLLUP 함수
- Subtotal 을 생성하기 위해 사용
- N+1 Level의 Subtotal 이 생성됨
- 계층구조이므로 인수 순서가 바뀌면 결과도 바뀜
SELECT COLUMN_NAME
FROM TABLE_NAME
WHERE ...
GROUP BY ROLLUP(COLUMN_NAME, ...);- GROUPING(EXPR) : ROLLUP, CUBE 에 의한 소계가 계산된 결과에는 1, 그 외에는 0
- GROUPING, CASE/DECODE : 소계를 나타내는 필드에 원하는 문자열 지정
- ROLLUP 함수 결합 사용 가능, 결합된 경우 하나의 집합으로 간주
3. CUBE 함수
- 결합 가능한 모든 값에 대하여 다차원 집계 생성
- ROLLUP에 비해 시스템 연산 대상이 많음
- 표시된 인수들에 대한 계층별 집계를 구할 수 있음
- 인수들 간 평등한 관계 → 인수의 순서가 바뀌는 경우, 정렬 순서는 바뀔 수 있어도 데이터 결과는 같음
- 명시적으로 정렬이 필요함
SELECT COLUMN_NAME
FROM TABLE_NAME
WHERE ...
GROUP BY CUBE(COLUMN_NAME, ...);4. GROUPING SETS 함수
- GROUP BY SQL 문장을 여러번 반복하지 않고 소계 집합 생성
- 표시된 인수들에 대한 개별 집계를 구함
- 인수들 간 평등한 관계 → 인수의 순서가 바뀌는 경우, 정렬 순서는 바뀔 수 있어도 데이터 결과는 같음
- 명시적으로 정렬이 필요함
SELECT COLUMN_NAME
FROM TABLE_NAME
WHERE ...
GROUP BY GROUPING SETS(COLUMN_NAME, ...);
Part 6. WINDOW 함수
1. WINDOW FUNCTION 개요
- 중첩해서 사용하지 못함
- 서브쿼리에서는 사용 가능
| 종류 | 함수 |
| 순위 관련 함수 | RANK, DENSE_RANK, ROW_NUMBER |
| 집계 관련 함수 | SUM, MAX, MIN, AVG, COUNT |
| 행 순서 관련 함수 | FIRST_VALUE, LAST_VALUE, LAG, LEAD |
| 비율 관련 함수 | CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT |
| 통계분석 관련 함수 | CORR, COVAR_POP, ..... 등 통계 특화 함수 |
- OVER 키워드가 필수 포함됨
SELECT WINDOW_FUNCTION (ARGUMENTS)
OVER ( [PARTITION BY COLUMN_NAME] [ORDER BY 절] [WINDOWING 절] )
FROM TABLE_NAME;- PARTITION BY : 전체 집합을 기준에 의해 소그룹으로 나눔
- WINDOWING : 함수의 대상이 되는 행 기준의 범위 지정 (SQL Server는 지원 안함)
• ROWS : 물리적인 결과 행의 수
[ROWS BETWEEN N PRECEDING AND M FOLLOWING] -- ORDER BY 필수, 앞 N건 ~ 뒤 M건을 범위로 지정
• RANGE : 논리적인 값에 의한 범위
[RANGE UNBOUNDED PRECEDING] -- ORDER BY 필수, 파티션 내의 첫번째 행까지의 범위 지정
2. 그룹 내 순위 함수
가. RANK 함수
- 특정 항목에 대한 순위를 구하는 함수
- 동일한 값에 대해서는 동일 순위 부여
- SELECT 절에서 사용
SELECT
RANK() OVER (
[PARTITION BY COLUMN_NAME]
ORDER BY COLUMN_NAME ASC|DESC -- 필수
) ALIAS
FROM TABLE_NAME;- DENSE_RANK() : 동일한 순위를 하나의 건수로 취급함
나. ROW_NUMBER 함수
- 동일한 값이라도 고유한 순위 부여
- 동일 값에 대한 순서까지 관리하려면 ORDER BY 절에 컬럼 추가
SELECT
ROW_NUMBER() OVER (
[PARTITION BY COLUMN_NAME]
ORDER BY COLUMN_NAME ASC|DESC -- 필수
) ALIAS
FROM TABLE_NAME;3. 일반 집계 함수
가. SUM 함수
SELECT
SUM(COLUMN_NAME)
OVER (
[PARTITION BY COLUMN_NAME]
[ORDER BY COLUMN_NAME ASC|DESC] -- SQL Server 에서는 지원하지 않음
[WINDOWING]
)
FROM TABLE_NAME;나. MAX, MIN 함수
SELECT
MAX|MIN(COLUMN_NAME)
OVER (
[PARTITION BY COLUMN_NAME]
[ORDER BY COLUMN_NAME ASC|DESC]
[WINDOWING]
)
FROM TABLE_NAME;다. AVG 함수
SELECT
AVG(COLUMN_NAME)
OVER (
[PARTITION BY COLUMN_NAME]
[ORDER BY COLUMN_NAME ASC|DESC]
[WINDOWING]
) ALIAS
FROM TABLE_NAME;라. COUNT 함수
SELECT
COUNT(*)
OVER (
[PARTITION BY COLUMN_NAME]
[ORDER BY COLUMN_NAME ASC|DESC]
[WINDOWING]
) ALIAS
FROM TABLE_NAME;4. 그룹 내 행 순서 함수
가. FIRST_VALUE 함수
- 가장 먼저 나온 값을 구함
- SQL Server 에서는 지원하지 않음
- MIN 함수와 같은 결과
SELECT
FIRST_VALUE(COLUMN_NAME)
OVER (
[PARTITION BY COLUMN_NAME]
[ORDER BY COLUMN_NAME ASC|DESC]
[WINDOWING]
) ALIAS
FROM TABLE_NAME;나. LAST_VALUE 함수
- 가장 나중에 나온 값을 구함
- SQL Server 에서는 지원하지 않음
- MAX 함수와 같은 결과
- 공동 등수를 인정하지 않고, 가장 나중에 나온 행만 처리
SELECT
LAST_VALUE(COLUMN_NAME)
OVER (
[PARTITION BY COLUMN_NAME]
[ORDER BY COLUMN_NAME ASC|DESC]
[WINDOWING]
) ALIAS
FROM TABLE_NAME;다. LAG 함수
- 이전 몇 번째 행의 값 가져옴
- SQL Server 에서는 지원하지 않음
SELECT
LAG(
COLUMN_NAME
[, N] -- 몇 번째 앞 행을 가져올지 지정, default. 1
[, NVL_VALUE] -- N번째 앞 행이 NULL 인 경우 대체값 (NVL)
)
OVER (
[PARTITION BY COLUMN_NAME]
ORDER BY COLUMN_NAME ASC|DESC -- 필수
)
FROM TABLE_NAME;라. LEAD 함수
- 이후 몇 번째 행의 값 가져옴
- SQL Server 에서는 지원하지 않음
SELECT
LEAD(
COLUMN_NAME
[, N] -- 몇 번째 뒤 행을 가져올지 지정, default. 1
[, NVL_VALUE] -- N번째 앞 행이 NULL 인 경우 대체값 (NVL)
)
OVER (
[PARTITION BY COLUMN_NAME]
ORDER BY COLUMN_NAME ASC|DESC -- 필수
)
FROM TABLE_NAME;5. 그룹 내 비율 함수
가. RATIO_TO_REPORT 함수
- 파티션 내 전체 SUM() 값에 대한 행별 컬럼 값의 백분율을 소수점으로 구함
- 0 < 결과값 ≤ 1 범위를 가짐
- 개별 RATIO 합 = 1
- SQL Server 에서는 지원하지 않음
SELECT
RATIO_TO_REPORT(COLUMN_NAME)
OVER ([PARTITION BY COLUMN_NAME])
FROM TABLE_NAME;나. PERCENT_RANK 함수
- 파티션별 윈도우에서 제일 먼저 나오는 것을 0, 제일 나중에 나오는것을 1로 하여, 행의 순서별 백분율을 구함
- 0 ≤ 결과값 ≤ 1 범위를 가짐
- SQL Server 에서는 지원하지 않음
SELECT
PERCENT_RANK()
OVER(
[PARTITION BY COLUMN_NAME]
ORDER BY COLUMN_NAME ASC|DESC -- 필수
)
FROM TABLE_NAME;다. CUME_DIST 함수
- 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율을 구함
- 0 < 결과값 ≤ 1 범위를 가짐
- SQL Server 에서는 지원하지 않음
SELECT
CUME_DIST()
OVER(
[PARTITION BY COLUMN_NAME]
ORDER BY COLUMN_NAME ASC|DESC -- 필수
)
FROM TABLE_NAME;라. NTILE 함수
- 전체 건수를 ARGUMENT 값으로 N 등분한 결과
SELECT
NTILE(N)
OVER(
[PARTITION BY COLUMN_NAME]
ORDER BY COLUMN_NAME ASC|DESC -- 필수
)
FROM TABLE_NAME;
Part 7. DCL
1. DCL 개요
- 유저를 생성하고 권한을 제어하는 명령어
2. 유저와 권한
- ORACLE은 유저를 통해 접근
| 기본유저 | 역할 |
| SCOTT | 샘플유저 (PWD : TIGER) |
| SYS | DBA ROLE 을 부여받은 유저 |
| SYSTEM | 모든 시스템 권한을 부여받은 DBA 유저 (PWD : ORACLE 설치 시 지정한 PWD) |
- SQL Server 는 '로그인' 생성 후 생성한 유저와 매핑 (Windows 인증, Windows 인증 + SQL 인증)
가. 유저 생성과 시스템 권한 부여
- 시스템 권한 : 각 동작을 실행할 수 있는 권한 (DDL 등)
- ROLE 을 이용하여 간편하고 쉽게 권한 부여 가능
GRANT [CREATE USER|CREATE TABLE|...] TO USER_NAME; -- 권한부여
[Oracle]
CREATE USER USER_NAME
IDENTIFIED BY PASSWORD;
[SQL Server]
CREATE LOGIN LOGIN_NAME
WITH PASSWORD='PASSWORD' -- 로그인생성
DEFAULT_DATABASE=DATABASE_NAME; -- 접속DB
CREATE USER USER_NAME -- 유저생성
FOR LOGIN LOGIN_NAME
WITH DEFAULT_SCHEMA=dbo;나. 오브젝트에 대한 권한 부여
- 다른 유저의 테이블에 접근하기 위해서는 소유자로부터 권한 부여 필요
- SELECT, INSERT, DELETE, UPDATE 등의 권한을 따로 관리
3. ROLE 을 이용한 권한 부여
- 권한들의 집합
- ROLE 을 다른 ROLE 에 부여할 수 있음
- 빠르고 정확한 권한 부여 가능
[ROLE 생성]
CREATE ROLE ROLE_NAME;
[ROLE에 권한 부여]
GRANT ... TO ROLE_NAME;
[사용자에 ROLE 부여]
GRANT ROLE_NAME TO USER_NAME;- Oracle에서는 기본 ROLE 제공
| ROLE | 권한 |
| CONNECT | ALTER TABLE, CREATE CLUSTER, CREATE DATABASE LINK, CREATE MENU_SEQUENCE, CREATE SESSION, CREATE SYNONYM, CREATE TABLE, CREATE VIEW |
| RESOURCE | CREATE CLUSTER, CREATE INDEXTYPE, CREATE OPERATOR, CREATE PROCEDURE, CREATE MENU_SEQUENCE, CREATE TABLE, CREATE TRIGGER, CREATE TYPE |
- SQL Server 에서는 기본 ROLE 에 멤버로 참여하는 방식
Part 8. 절차형 SQL
1. 절차형 SQL 개요
- 절차 지향적인 프로그램이 가능하도록 제공
- SQL 문의 연속적인 실행이나 조건에 따른 분기처리를 이용하여 특정 기능을 수행하는 저장 모듈 생성
2. PL/SQL 개요 (Oracle)
가. PL/SQL 특징
PL/SQL 특징?
- Block 구조
- 기능별로 모듈화 가능
- 변수, 상수 등을 선언하여 값 교환 가능
- IF, LOOP 같은 절차형 언어 사용 가능
- 에러를 정의하여 사용 가능
- Oracle 에 내장되어 있음
- 응용 프로그램 성능 향상
- 트랜잭션 언어이므로 통신량을 줄일 수 있음
- 저장모듈 개발 가능
- 독립적으로 실행되거나 다른 프로그램으로부터 실행될 수 있음
- 저장모듈 : PL/SQL 문장을 DB 서버에 저장하여 사용자와 앱 간 공유할 수 있도록 만든 SQL 컴포넌트 프로그램
- Oracle 에서의 종류 : PROCEDURE, USER DEFINED FUNCTION, TRIGGER
- SQL 문장과 구분하여 처리함
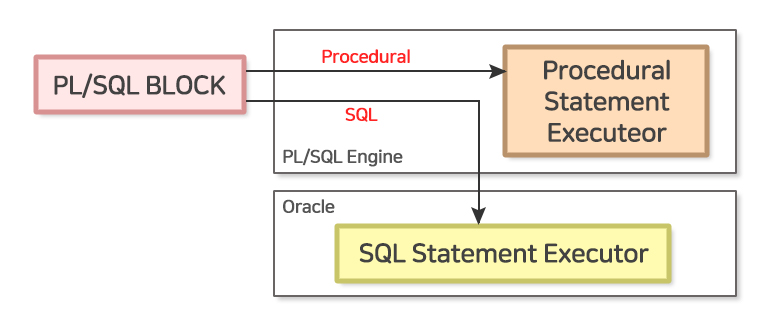
나. PL/SQL 구조

다. PL/SQL 기본 문법
[프로시저 생성]
CREATE [OR REPLACE] PROCEDURE PROCEDURE_NAME (
ARGUMENT_NAME [MODE] DATA_TYPE,
...
)
IS [AS]
...
BEGIN
...
[EXCEPTION]
...
END;
[프로시저 삭제]
DROP PROCEDURE PROCEDURE_NAME;- MODE
| 모드 | 설명 |
| IN | 운영체제에서 프로시저로 전달 될 변수의 모드 |
| OUT | 프로시저에서 처리 된 결과가 운영체제로 전라되는 모드 |
| INOUT | in, out 두 가지 기능ㅇㄹ 동시에 수행하는 모드 |
3. T-SQL 개요 (SQL Server)
가. T-SQL 특징
T-SQL 특징?
- @@ 전역변수, @ 지역변수
- int, float, varchar 등의 자료형 제공
- 산술연산자, 비교연산자, 논리연산자 사용 가능
- IF-ELSE, WHILE, CASE-THEN 사용 가능
- 주석 가능 (-- 한줄주석, /* */ 범위주석)
나. T-SQL 구조
다. T-SQL 기본 문법
[프로시저 생성|수정]
CREATE|ALTER PROCEDURE [SCHEMA_NAME, ]PROCEDURE_NAME (
@ARGUMENT_NAME DATA_TYPE [MODE],
...
)
WITH AS
...
BEGIN
...
[ERROR]
...
END;
[프로시저 삭제]
DROP PROCEDURE [SCHEMA_NAME, ]PROCEDURE_NAME;- MODE
| 모드 | 설명 |
| VARYING | 출력 매개변수로 사용, CURSOR 매개변수에만 적용 |
| DEFAULT | 기본값 처리 |
| OUT, OUTPUT | 처리한 결과 값을 EXECUTE 문 호출 시 반환 |
| READONLY | 자주 사용하지 않음, 프로시저 본문 내에서 매개변수를 업데이트하거나 수정할 수 없음 |
- WITH options
| 옵션 | 설명 |
| RECOMPILE | 현재 프로시저 계획을 캐시하지 않고 런타임에 컴파일, 개별 쿼리에 대한 계획을 삭제할 때 사용 |
| ENCRYPTION | 알아보기 어려운 형식을 변환됨, 원본 백업 필요 |
| EXECUTE AS | 프로시저를 실행할 보안 컨텍스트 지정 |
4. 프로시저의 생성과 활용
- SCALAR 변수 : 사용자의 임시 데이터를 하나만 저장할 수 있는 변수, 거의 모든 형태의 데이터 유형 지정 가능
- SELECT 문장은 반드시 결과값 한 개여야 함 (없거나 여러개인 경우 에러)
- 대입 연산자는 := 를 사용
- EXCEPTION 에서는 WHEN~THEN 으로 에러 종류별 처리
5. User Defined Function 의 생성과 활용
- 데이터베이스 내에 저장해 놓은 명령문의 집합
- 사용자가 별도의 함수를 만듬
- RETURN 을 사용하여 하나의 값을 반드시 되돌려 줘야 함
[Oracle]
CREATE OR REPLACE FUNCTION FUNCTION_NAME
(v_input in DATATYPE) -- 입력값
return DATATYPE
IS
v_return VAR_NAME := VALUE; -- return 값 저장 변수
BEGIN
...
v_return := VALUE; -- return 변수에 값 저장
RETURN v_return;
END;
[SQL Server]
CREATE FUNCTION FUNCTION_NAME
(@v_input DATA_TYPE) -- 입력값
RETURNS DATA_TYPE
AS
BEGIN
DECLARE @v_return DATATYPE -- return 값 저장 변수
SET @v_return = VALUE -- return 변수에 값 저장
...
RETURN @v_return;
END;6. Trigger 의 생성과 활용
- 테이블에 DML 문이 수행되었을 때, DB에서 자동으로 동작하도록 작성된 프로그램
- 테이블, 뷰, 데이터베이스 작업을 대상으로 정의 가능
- 전체 트랜잭션 작업에 대해 발생되는 Trigger VS 각 행에 대해서 발생되는 Trigger
[Oracle]
CREATE OR REPLACE TRIGGER TRIGGER_NAME
AFTER INSERT -- 발생시점
ON TABLE_NAME -- 대상테이블
FOR EACH ROW -- 행별/트랜잭션별
DECLARE
-- 확인할 데이터
VAR_NAME TABLE.COLUMN_NAME%TYPE,
...
BEGIN
...
-- :OLD 기존 데이터 값
-- :NEW 새로 입력 된 데이터
END;
[SQL Server]
CREATE TRIGGER TRIGGER_NAME
ON TABLE_NAME -- 대상테이블
AFTER INSERT -- 발생시점
AS
DECLARE
-- 확인할 데이터
@VAR_NAME DATA_TYPE,
...
BEGIN
...
-- deleted 기존 데이터 값
-- inserted 새로 입력 된 데이터
END- Trigger에서 사용하는 레코드 구조체 비교
| 구분 | :OLD / deleted | :NEW / inserted |
| INSERT | NULL | 입력된 레코드 값 |
| UPDATE | UPDATE 되기 전의 레코드 값 | UPDATE 된 후의 레코드 값 |
| DELETE | 레코드가 삭제되기 전 값 | NULL |
- 데이터베이스 보안의 적용, 유효하지 않은 트랜잭션의 예방, 업무 규칙 자동 적용 제공 등에 사용
7. 프로시저와 트리거의 차이점
| 프로시저 | 트리거 |
| CREATE Procedure 문법 사용 | CREATE Trigger 문법 사용 |
| EXECUTE 명령어로 실행 | 생성 후 자동 실행 |
| COMMIT, ROLLBACK 실행 가능 | COMMIT, ROLLBACK 실행 안됨 |
'Study > Database' 카테고리의 다른 글
| [ADsP] 시험 과목 정리 (0) | 2023.07.24 |
|---|---|
| [SQLP] 과목 2. SQL 기본 및 활용 - (3) SQL 최적화 기본 원리 (0) | 2022.01.04 |
| [SQLP] 과목 2. SQL 기본 및 활용 - (1) SQL 기본 (0) | 2021.12.28 |
| [SQLP] 과목 1. 데이터 모델링의 이해 - (2) 데이터 모델과 성능 (0) | 2021.12.23 |
| [SQLP] 과목 1. 데이터 모델링의 이해 - (1) 데이터 모델링의 이해 (0) | 2021.12.20 |
| [SQLP] 시험 과목 정리 (0) | 2021.12.08 |
| [SQLP] 이론 7. 백업 및 복구 (0) | 2021.12.08 |
| [SQLP] 이론 6. 테이블 설계 (0) | 2021.12.08 |
| [SQLP] 이론 5. Transaction (0) | 2021.12.03 |
| [SQL] VIEW (0) | 2021.12.03 |